


Ah, the bright glow of computer screens. A beacon ...
news-extra-space

 Image credit: arstechnica[/caption]
According to Cerebras, "near-perfect scaling" describes how training time for neural networks is decreased as more CS-2 computer units are added to Andromeda. Typically, when hardware costs grow, the benefits of scaling up a deep-learning model by increasing compute capacity on GPU-based systems may become less favorable. Additionally, Cerebras asserts that its supercomputer is capable of jobs that GPU-based systems are not: " GPU impossible work was demonstrated by one of Andromeda’s first users, who achieved near perfect scaling on GPT-J at 2.5 billion and 25 billion parameters with long sequence lengths—MSL of 10,240. The users attempted to do the same work on Polaris, a 2,000 Nvidia A100 cluster, and the GPUs were unable to do the work because of GPU memory and memory bandwidth limitations."
It remains to be seen if those assertions can withstand external inspection, but Cerebras seems to be presenting an option in a time when businesses frequently train deep-learning models on escalating Nvidia GPU clusters.
Image credit: arstechnica[/caption]
According to Cerebras, "near-perfect scaling" describes how training time for neural networks is decreased as more CS-2 computer units are added to Andromeda. Typically, when hardware costs grow, the benefits of scaling up a deep-learning model by increasing compute capacity on GPU-based systems may become less favorable. Additionally, Cerebras asserts that its supercomputer is capable of jobs that GPU-based systems are not: " GPU impossible work was demonstrated by one of Andromeda’s first users, who achieved near perfect scaling on GPT-J at 2.5 billion and 25 billion parameters with long sequence lengths—MSL of 10,240. The users attempted to do the same work on Polaris, a 2,000 Nvidia A100 cluster, and the GPUs were unable to do the work because of GPU memory and memory bandwidth limitations."
It remains to be seen if those assertions can withstand external inspection, but Cerebras seems to be presenting an option in a time when businesses frequently train deep-learning models on escalating Nvidia GPU clusters.

Leave a Reply







Ah, the bright glow of computer screens. A beacon ...

Are you facing the E87 Steam login error while try...

Google Slides is a popular tool for making and sha...
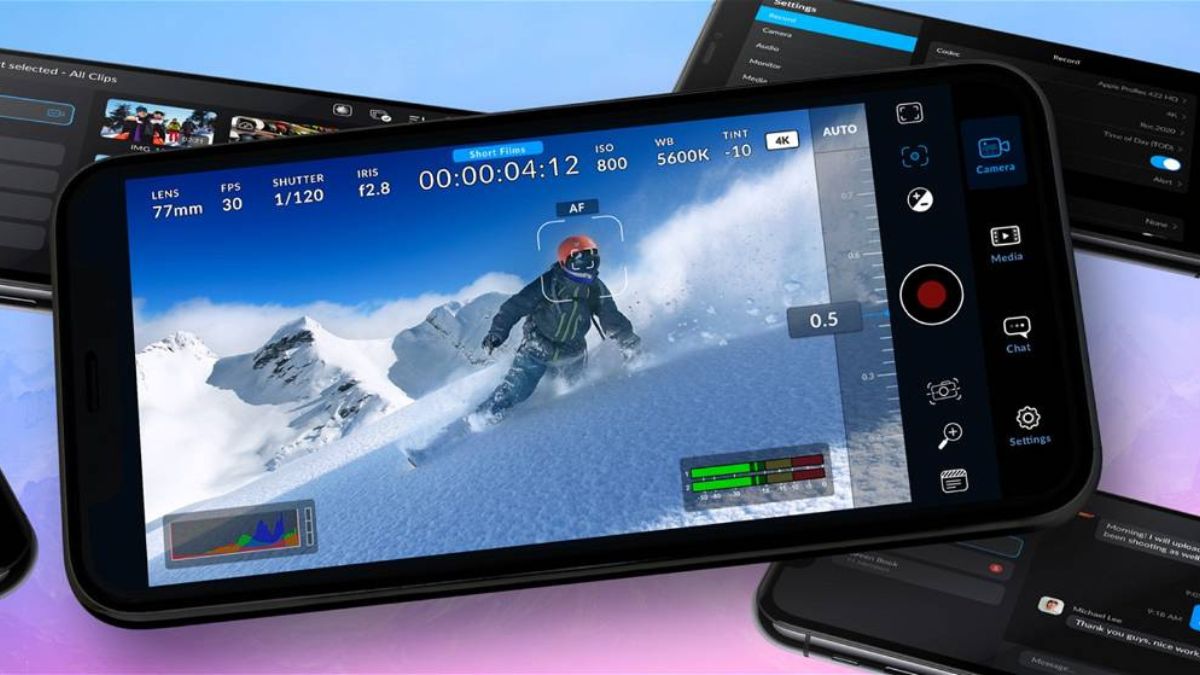
(Image credit- Gearrice) Blackmagic Design has ...

(Image credit- Tool Finder) You will soon have ...

(Image credit- Tech Times) Field-Programmable G...