OpenAI Unveils New Text-To-3D System—Downloadable as Open-Source Software!
May 16, 2023 By Raulf Hernes

(Image Credit Google)
(Image credit- NVIDIA Developer)
With its most recent creation, the Shap-E AI text-to-3D object technology, which was initially published by New Atlas, OpenAI has achieved major advancements.
This generative AI program, which is open-source and may be downloaded, can create 3D items straight from word descriptions or even from provided photographs.
"Implicit Functions"
OpenAI debuted a technology that could convert text inputs into simple 3D models in the form of point clouds in a prior release dubbed Point-E.
The new Shap-E system, however, marks a significant advancement since in addition to being faster, it can also create models as "implicit functions."
These are mathematical functions that can be represented as textured meshes or neural radiance fields (NeRFs), which are 3D models produced by machine learning from 2D photos.
[caption id="" align="aligncenter" width="637"]

Image credit- Tech Crunch[/caption]
The prospective applications are really exciting, even though the technical parts could appear difficult. These 3D models are created with downstream uses in mind, opening up intriguing possibilities.
The use of this technology in VR/AR applications could pave the way for verbally-programmed 3D visual effects and allow for the creation of virtual companions as well as customized homes and clothes.
Shap-E is anticipated to smoothly integrate with 3D printing as its capabilities develop. This implies that the shapes produced by these
AI systems may soon turn into higher-quality, real-world physical items.
In the future, users might communicate with an AI assistant powered by a language model rather than the system itself in order to provide the right prompts for the 3D-maker AI and produce outputs that are more accurate and efficient.
[caption id="" align="aligncenter" width="1023"]
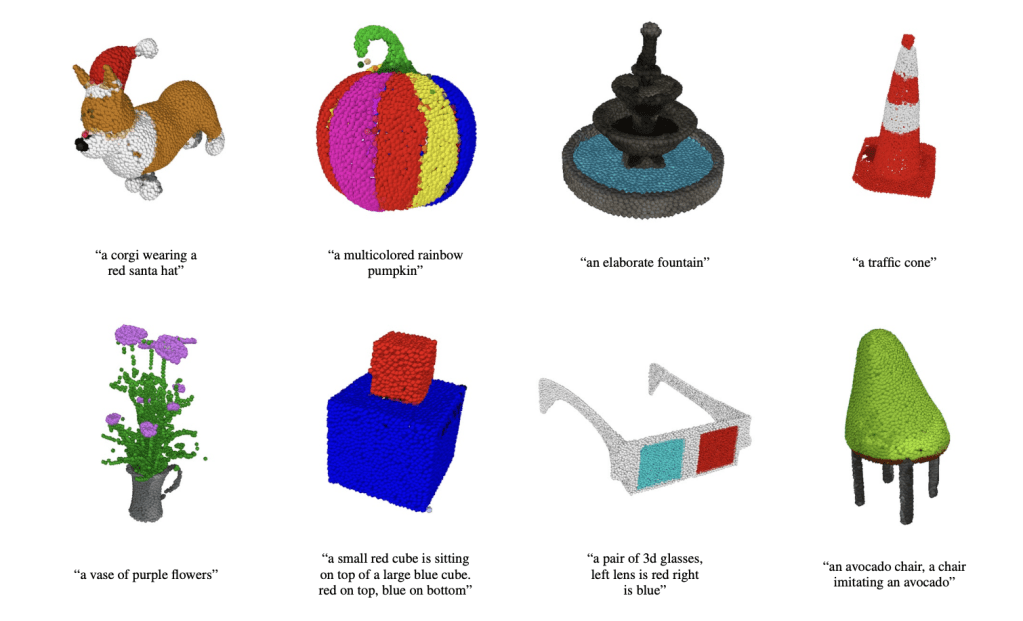
Image credit- TechCrunch[/caption]
Model for Conditional Generated
Shap-E, a ground-breaking conditional generative model for 3D objects, is presented by OpenAI. Shap-E directly creates the parameters of implicit functions that may be represented as both textured meshes and neural radiance fields, in contrast to earlier 3D generative models that only produced a single output representation.
A conditional diffusion model is developed utilizing the encoder's outputs after the first stage in which an encoder is taught to map 3D assets into implicit function parameters.
The generated models demonstrate the ability to build intricate and varied 3D assets in a matter of seconds after training on a sizable dataset of paired 3D and text data.
Also read:
Apple’s AR/VR headset expected to be unveiled at WWDC in June
The researchers behind the new system claim that while modeling a higher-dimensional, multi-representation output space, Shap-E exhibits faster convergence and achieves equivalent or even superior sample quality to Point-E, an explicit generative model over point clouds.
In order to encourage additional research and advancement in the subject, OpenAI has made the model weights, inference code, and samples available to the general public. It can be found here.